This post covers,
- Information about the data dictionary
- Interview questions for Data Dictionary Database tables along with answers
This is compiled to help SAP ABAP Developers and Freshers to prepare for a SAP ABAP interview. It is compiled from various resources available over the internet and referring to SAP documentation.
How to prepare for SAP ABAP Interviews using this resource?
- Read the question
- Think of the answer
- Read the answer to see what you have missed
- Refer the screenshots / videos to visualize
- Refer the links provided to get detailed understanding
- Try doing hands-on
- Contact us for any further help by submitting your query on the form available on the link,
What interviewer may look for?
| Basic Level | Are you able to create database table, assign foreign key, search help, create index? |
| Medium Level | Are you able to understand different types of tables, various levels of search helps a field can have? |
| Advanced Level | Do you understand the significance of technical settings and are able to design a table as per the application requirement? Do you understand impact of enabling buffering, creating index etc on the performance? |
This is compiled to help SAP ABAP Developers and Freshers to prepare for a SAP ABAP interview. It is compiled from various resources available over the internet and referring to SAP documentation.
How to prepare for SAP ABAP Interviews using this resource?
- Read the question
- Think of the answer
- Read the answer to see what you have missed
- Refer the screenshots / videos to visualize
- Refer the links provided to get detailed understanding
- Try doing hands-on
- Contact us for any further help by submitting your query on the form available on the link,
Data Dictionary (DDIC)
Data Dictionary is –
- A central repository of all data objects used in SAP applications.
- A too to manage data objects, such as tables, views, data elements, domains, etc
Data Dictionary –
- Helps developers to define data objects in a consistent and reusable way
- Provides a graphical user interface that makes it easy for developers to define and manage data objects
Transaction code for Data Dictionary : SE11

Questions
Q1. What are the different data objects that can be created in Data Dictionary?
Q2. How to create a custom database table?
Q3. What is a delivery class in a database table?
Q6. What are the different Buffering Types and when can we use them?
Q7. How to enable the data change log for the table?
Q8. What is the difference in a column store and a row store table?
Q9. What are the advantages of column store over row store?
Q10. What is the use of a foreign key and how to assign it?
Q11. What is the difference in a value table and a check table?
Q12. How to provide a search help/F4 help/input help to the table field?
Q13. What is the additional information that we need to provide for any amount or quantity field?
Q14. What do we keep in mind while creating a secondary index on database table?
Q15. What are the different types of database tables and what is the difference between them?
Q16. What is difference in client dependent and client independent table?
Q1. What are the different data objects that can be created in Data Dictionary?
The main objects in the ABAP Dictionary are as follows:
- Database table
- Transparent Table, Pooled Table, Cluster Table
- View
- Database view, Projection view, Maintenance view, Help view
- Data type
- Data element, Structure, Table Type
- Type Groups
- Domain
- Search help
- Lock Object
Q2. How to create a custom database table?
The process to create a custom transparent database table is as below –
- Go to transaction SE11 and choose the radio button
Database table - Provide table name such as
'ZJP_TRAINING'and click on theCreatebutton - Maintain information in tab –
Delivery and Maintenanceto provideShort Description– Any meaning full descriptionDelivery Class– A for application table and C for customizing table. There are other options available but A & C are the most common ones.Data Browser/Table View Editing– Select value from the drop-down. If the data needs to be displayed or maintained, select the optionData/Maintenance Allowed
- Move to the tab –
Fieldsand maintain the field list required for the table- First field will usually be the client field (
MANDT) to make the table client dependent. It will also be a key field. - The table needs to be have at least one more primary key field
- The fields can refer to existing data elements or a new data element can be created
- It is possible to use Build-In Types directly – but it is not recommended
- First field will usually be the client field (
- Assign search help to fields in tab
Input Help/Checkcan be used. This is optional step. - Assign currency and quantity reference in tab –
Currency/Quantity Fields. This is optional step if there are no currency and/or quantity fields - Maintain
Technical SettingsData Class– Usually valuesAPPL0,APPL1,APPL2,USERorUSER1can be used depending on type of the tableSize Category– Values from 0 to 9 can be used depending on estimated number of rows in the tableSharing Type– Needed only in multi-tenancy environmentsBuffering– This is usually not turned on for custom tablesData changes– Data changes can be enabled using this checkbox.DB-Specific Properties– Here, either arow storeorcolumn storeis selected asStorage type
- Go to Extras > Enhancement categories and maintain a category. This is also an option step, but we get a warning while activation if this step is not performed.
- Save the table in a package and activate the table.
Note: Indexes can also be created in the tab Index. This is usually not a requirement for custom table.
Q3. What is a delivery class in a database table?
The delivery class of a database table controls the transport of table data in
- Installations
- Upgrades
- Client copies
- Transports between customer systems
Delivery class A and C are the most common. While creating a new custom table,
- A is used for master and transaction data table
- C is used for customizing table

Q4. What are the various technical settings that are required to be maintained for the table? What is the significance of each of them?
While creating a new custom table, Technical settings are mandatory. Without maintaining technical settings, a table can not be activated.
Data ClassSize CategorySharing TypeBufferingLog Data ChangesDB-Specific Properties
Data class
- Physical area of database where the database table is stored.
- The data class should be selected based on the kind of data to be stored in the table like
Master Data(APPL0),Transaction Data(APPL1),Organization and Customizing data(APPL2). - Additional
USERandUSER1data classes are provided for customers.
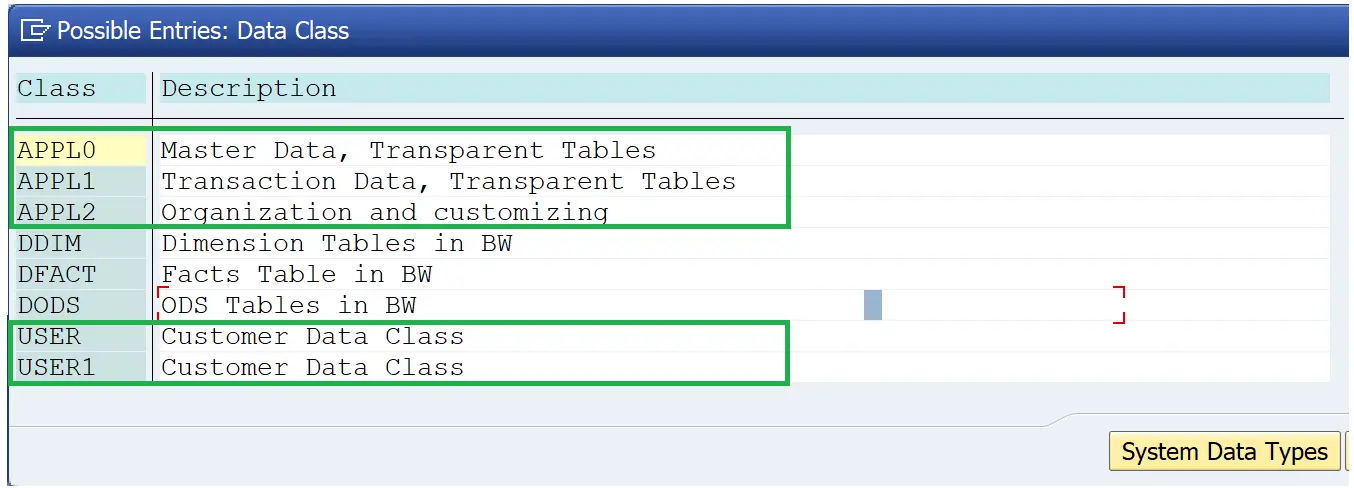
Size category
The size category determines the size of the initial memory reserved for the table on the database. When the table is activated, the initial memory is reserved for the table using the size category.
- If 0 is selected, the memory for 5100 records will be reserved in the below case.
- Values between 0 and 9 can be specified and intervals of expected rows are assigned to these values.
- The interval limits assigned to each size category depend on the structure of the database table.
- If the initial space reserved is exceeded, a new memory area is added implicitly in accordance with the chosen size category.
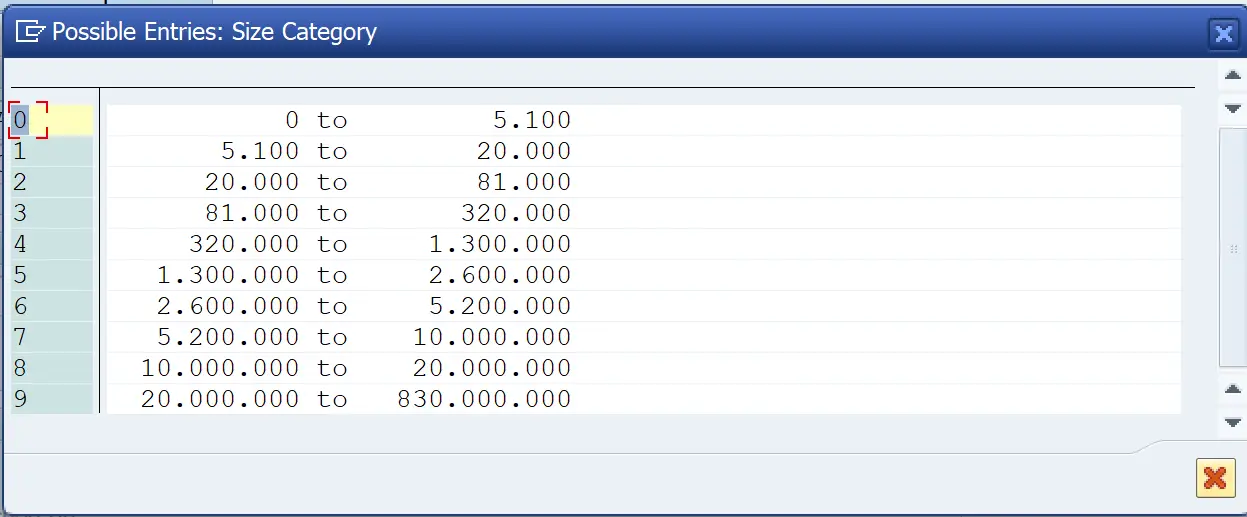
Table Buffering of Database Tables
For custom tables, we usually do not switch on the buffering as the custom tables have limited use in the applications.
- Buffering not allowed – Table buffering is not performed for the table.
- Buffering allowed, but switched off – Table buffering is not performed for the table when delivered. This setting indicates, however, that buffering is possible in principle and can be activated in other systems depending on how the table is used.
- Buffering switched on – Table buffering is performed for the table
Buffering Type
- Single record buffering – Only accessed rows are put in buffer. This type is recommended for large tables from which single rows are often read using
SELECT SINGLE. - Generic buffering – All rows that match with the accessed row for the number of keys specified. Generic buffering should be used if usually only certain areas of the table or view are required. These areas should not be too small, to prevent too many of them from being created and overloading buffer management. They should also not be too big, to prevent too much data from being loaded.
- Full buffering – When a row is read, all rows in the table or view are loaded to the SAP buffer. Full buffering should be used in small tables, such as customizing tables.
Note : For single record buffer – If SELECT SINGLE is used to access a non-buffered row, an attempt is made to load the row. If the row is not found, this is noted in the buffer and the database is not accessed again the next time SELECT SINGLE is used.
For buffered tables, the read requests to non-existing data is very fast as the failed attempts to fetch the data are loaded in the buffer and next such accesses are faster.
Log Data Changes
Data changes are logged in the log table DBTABLOG. The changes can also be analyzed using transaction SCU3. This also requires the profile parameter rec/client to be set to one of the following.
ALL( Logging is cross-client )clnt1, clnt2, ... ( Changes are logged only in the specified clients clnt1, clnt2, … )OFF(No logging)
If logging is activated, access to the database table slows down and lock situations can arise for the log table. Hence, the logging is not set up in the systems usually.
DB-Specific Properties
Either a row store or column store is selected as Storage type.
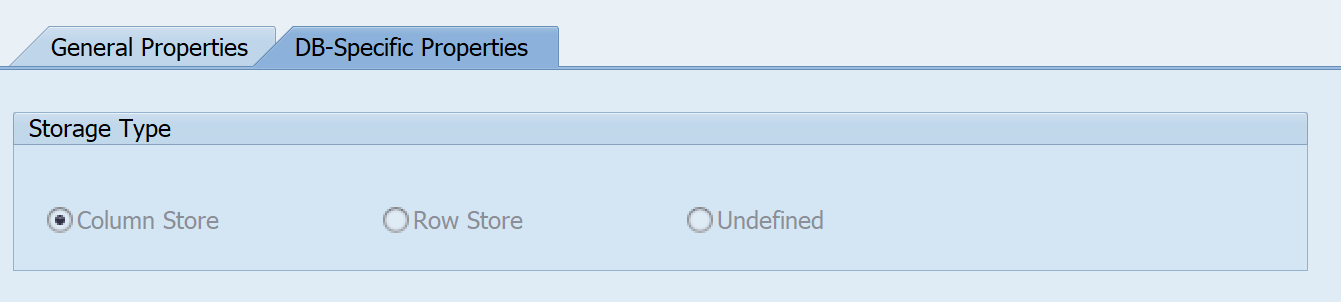
The data is stored in different way in row and column store. In HANA dB, the preference is to use Column Store.
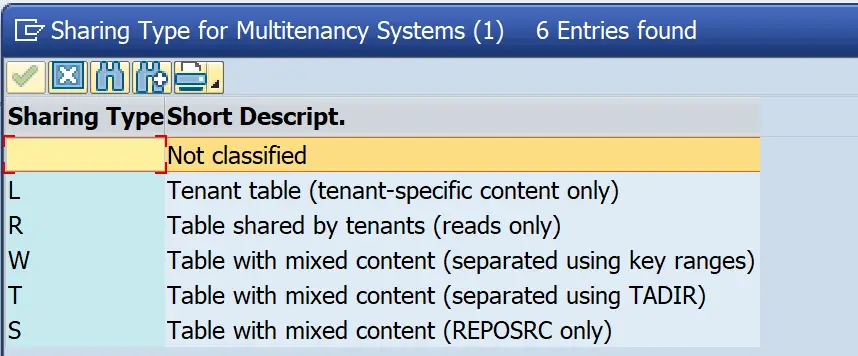
Sharing Type
Needed only in multi-tenancy environments. This value defines whether or not the table can be shared or not and what type is used for sharing.
Q5. How do you choose a size category? What happens when the number of records limit in size category is exceeded?
Size category value range is from 0 to 9. The size category is chosen based on estimated number of records that the table is expected to store. The number of records are not same for each table and it depends on the size of each record in the table.
0, 1 or 2 are the most common size category used for custom tables as they usually contain less data.
Size category only determines the initial size of the space reserved for the table.
If the initial space reserved is exceeded, a new memory area is added implicitly in accordance with the chosen size category.
Q6. What are the different Buffering Types and when can we use them?
SAP provides following Buffering Types
Single record buffering
- As this type puts only accessed rows in buffer, this type is recommended for large tables from which single rows are often read using
SELECT SINGLE. - For example, a certain orders are accessed by users multiple times where the order is fetched from order table using
SELECT SINGLE.
Generic buffering
- All rows that match with the accessed row for the number of keys specified.
- Generic buffering should be used if usually only certain areas of the table or view are required.
- For example, users working on a specific purchasing org and plant with the tables with frequent access having these fields as the first two fields. The Generic buffering with no. of key fields 2 can be used.
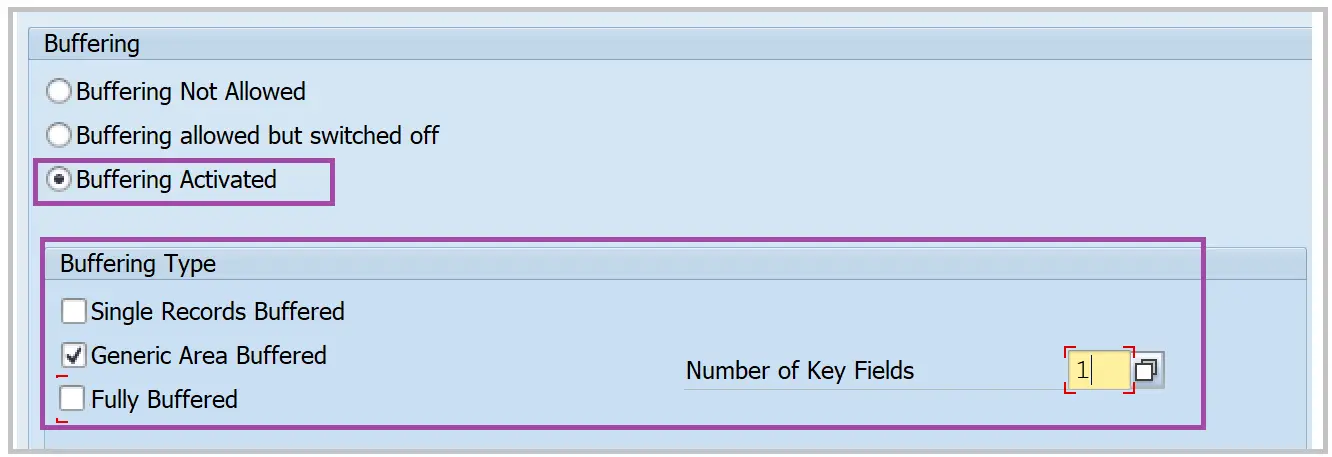
Full buffering
- When a row is read, all rows in the table or view are loaded to the SAP buffer.
- Full buffering should be used in small tables, such as customizing tables which are frequently used.
- For example, T000 has very field entries and is used frequently.
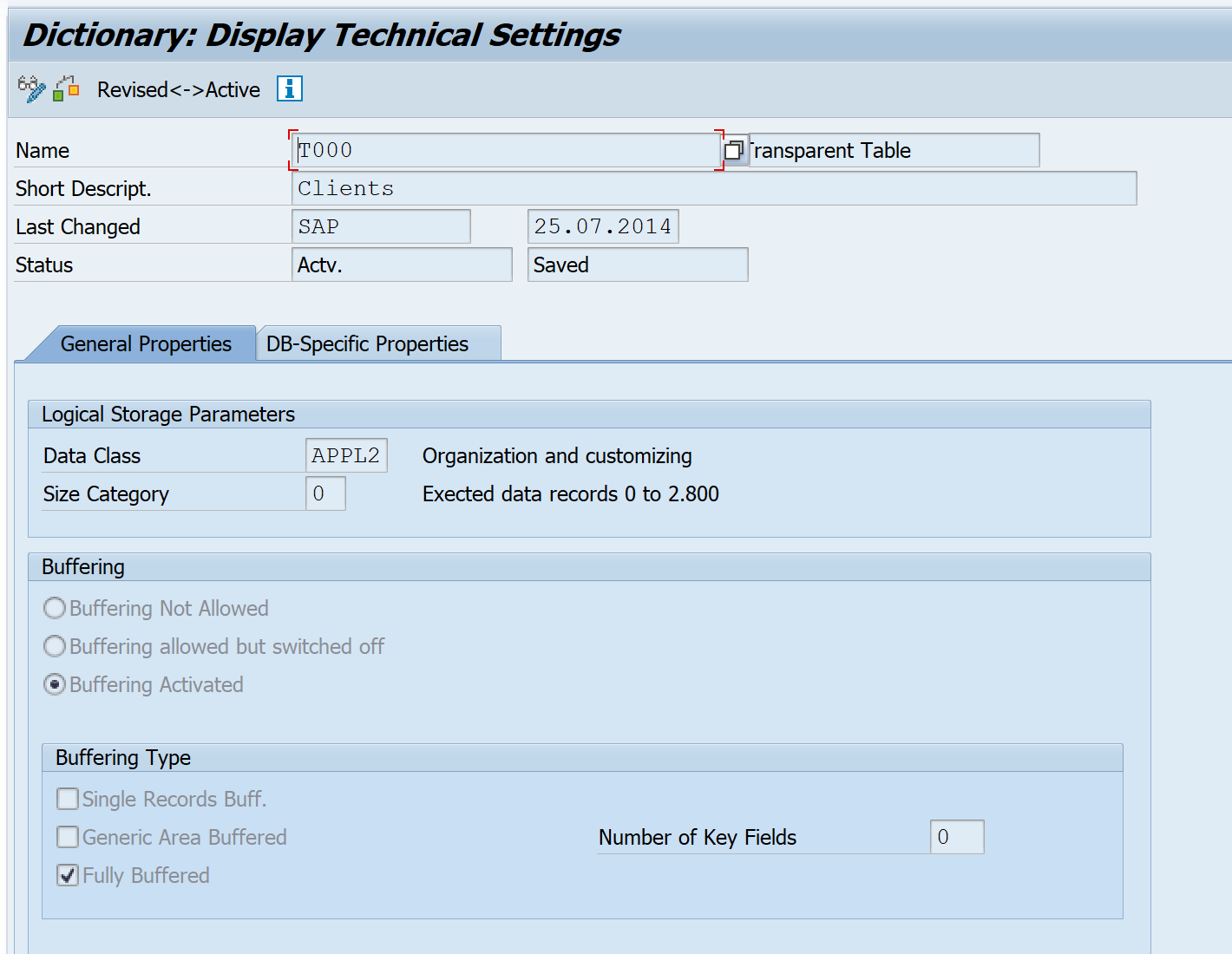
Q7. How to enable the data change log for the table?
Database table can be enabled for change log in the technical settings.
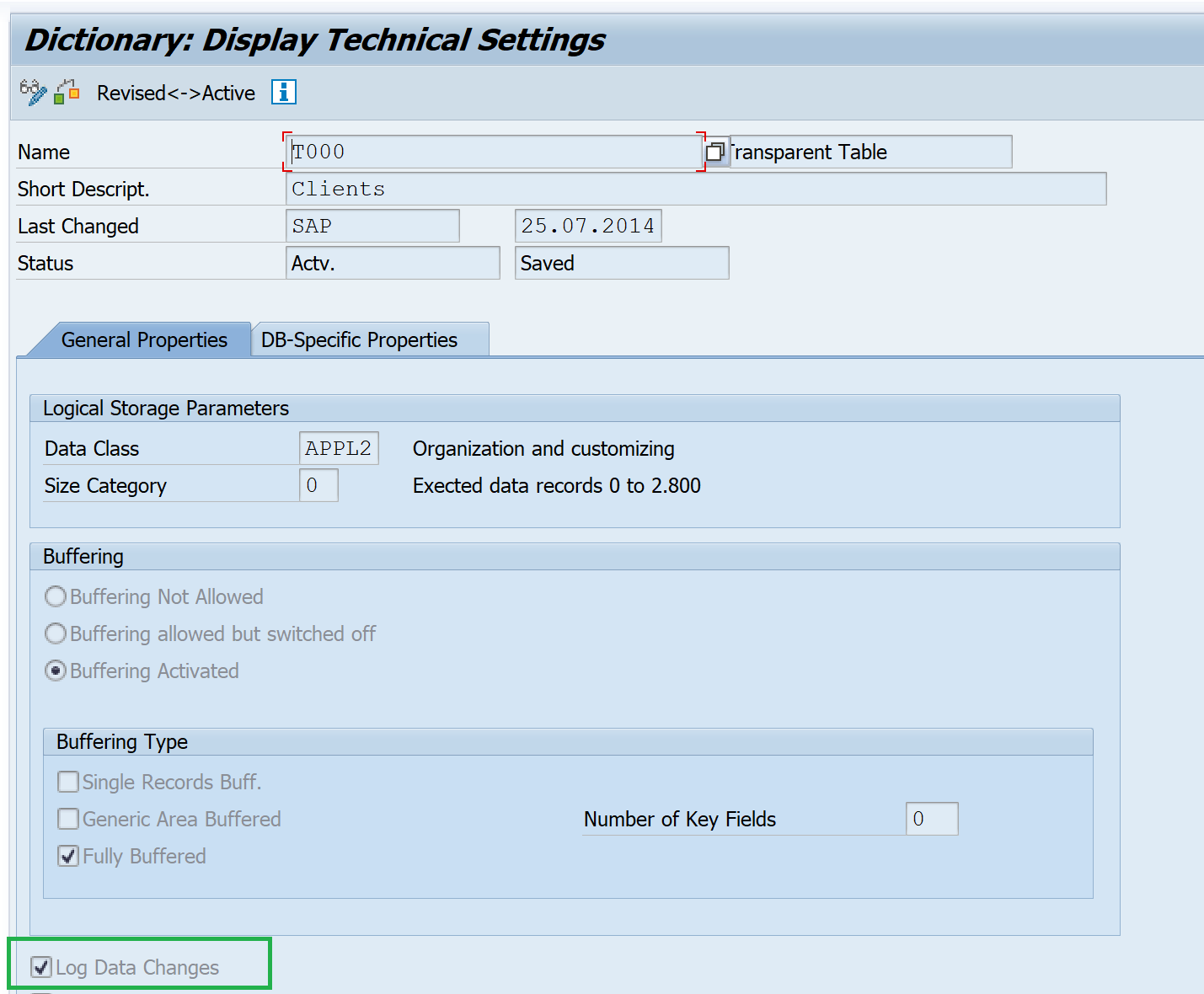
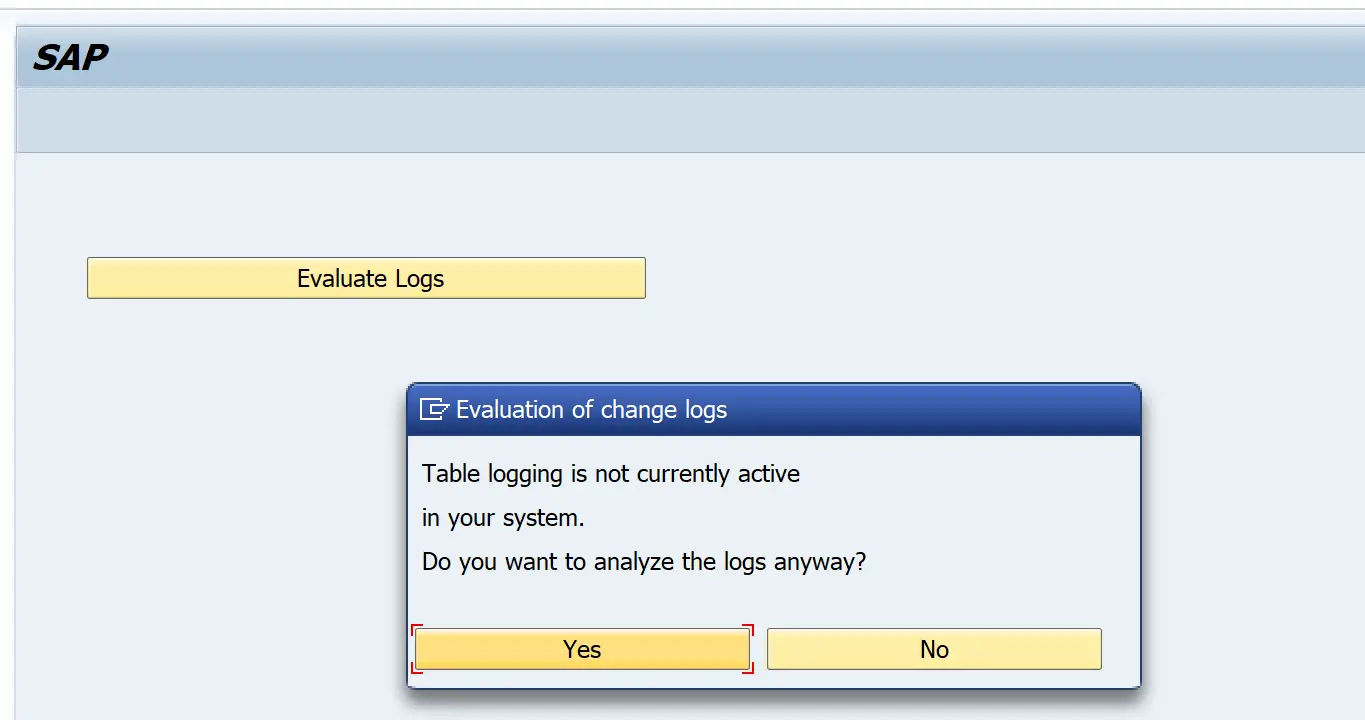
The profile parameter rec/client to be set to one of the following.
ALL( Logging is cross-client )clnt1, clnt2, ... ( Changes are logged only in the specified clients clnt1, clnt2, … )
If this parameter is not set, the SCU3 transaction shows below pop up.
Q8. What is the difference in a column store and a row store table?
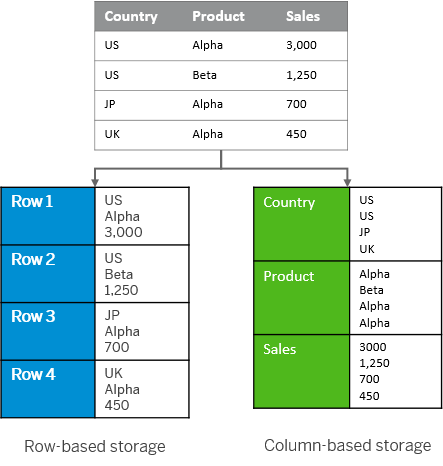
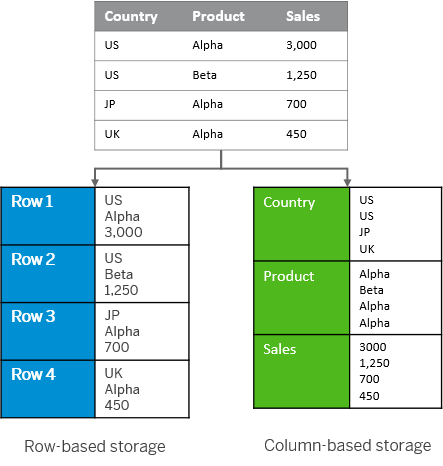
A database table has rows and columns. This is two dimensional data structure. However, in the memory, this is organized as a linear sequence.
For storing a table in linear memory, a row store stores or a column store can be chosen.
Row Store – A sequence of records that contains the fields of one row in the table together
- The application needs to process only one single record at one time
- The application typically needs to access the complete record.
- The columns contain mainly distinct values so compression rate would be low.
- Neither aggregations nor fast searching are required.
- The table has a small number of rows (for example, configuration tables).
Column Store – A sequence of records that contains the entries of the column together of one row in the table
- Calculations are typically executed on individual or a small number of columns.
- The table is searched based on the values of a few columns.
- The table has a large number of columns.
- The table has a large number of rows and columnar operations are required (for example, aggregation)
- Majority of the columns contain only a few distinct values leading to higher compression rate
Q9. What are the advantages of column store over row store?
Advantages of Column Store –
- Higher data compression rates
- Columnar data storage allows for highly efficient compression.
- Compression rate is higher when the columns have fewer distinct values.
- Higher performance for column operations
- Operations on single columns, such as searching or aggregations are faster
- Elimination of additional indexes
- The column-scanning speed of the in-memory column store and the compression mechanisms allow faster read operations, hence additional indexes are not required.
- Elimination of materialized aggregates
- It possible to calculate aggregates on large amounts of data on the fly with high performance.
- This eliminates the need for materialized aggregates leading to simplified data model and aggregation logic
- It allows for a higher level of concurrency because write operations do not require exclusive locks for updating aggregated values
- It ensures that the aggregated values are always up-to-date
- Parallelization
- Simplifies parallel execution using multiple processor cores as operations on different columns can be processed in parallel.
Q10. What is the use of a foreign key and how to assign it?
A foreign keys defines the relationships between tables in the ABAP Dictionary. It also creates a value checks for input fields. While creating a view or a lock object, only the tables connected with a foreign keys can be used together.
To assign a foreign key
- On the field maintenance screen of the table, select the check field and choose
 .
. - If the domain of the field has a value table, system can create a proposal with the value table as a check table.
- If the domain does not have a value table the screen for foreign key maintenance appears without proposals. In this case, enter the check table and save your entries.
- Cardinality such as 1:N can be specified
- Choose
 .
.
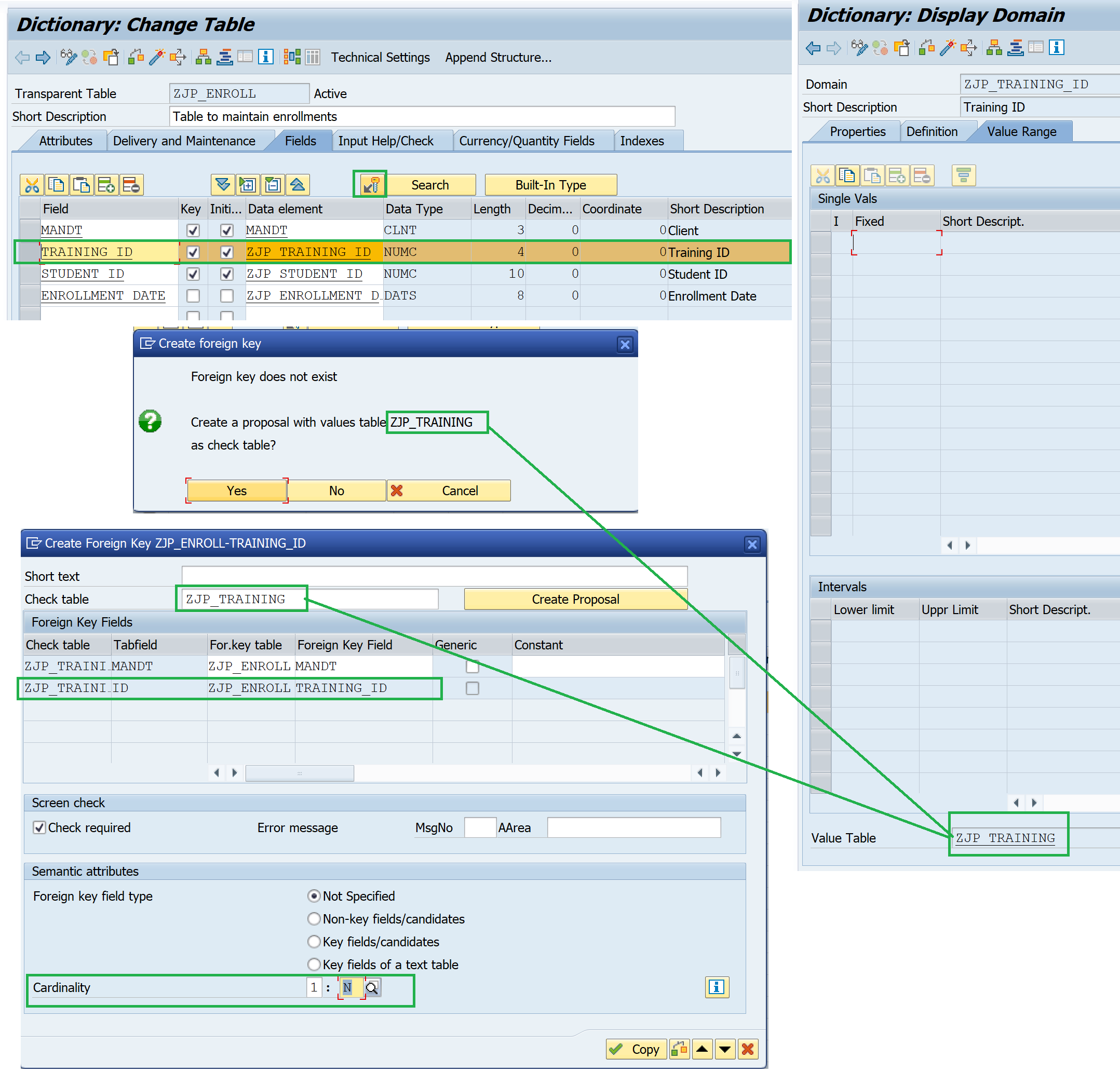
Q11. What is the difference in a value table and a check table?
Check Table
- Assigned using a foreign key to carry out the check for input values for the table field.
- Validation at the field level.
- For example, table
SCARRis assigned as a check table for table-fieldSPFLI-CARRID. Only theCARRIDvalues available in tableSCARRcan be used to create entries inSPFLI.
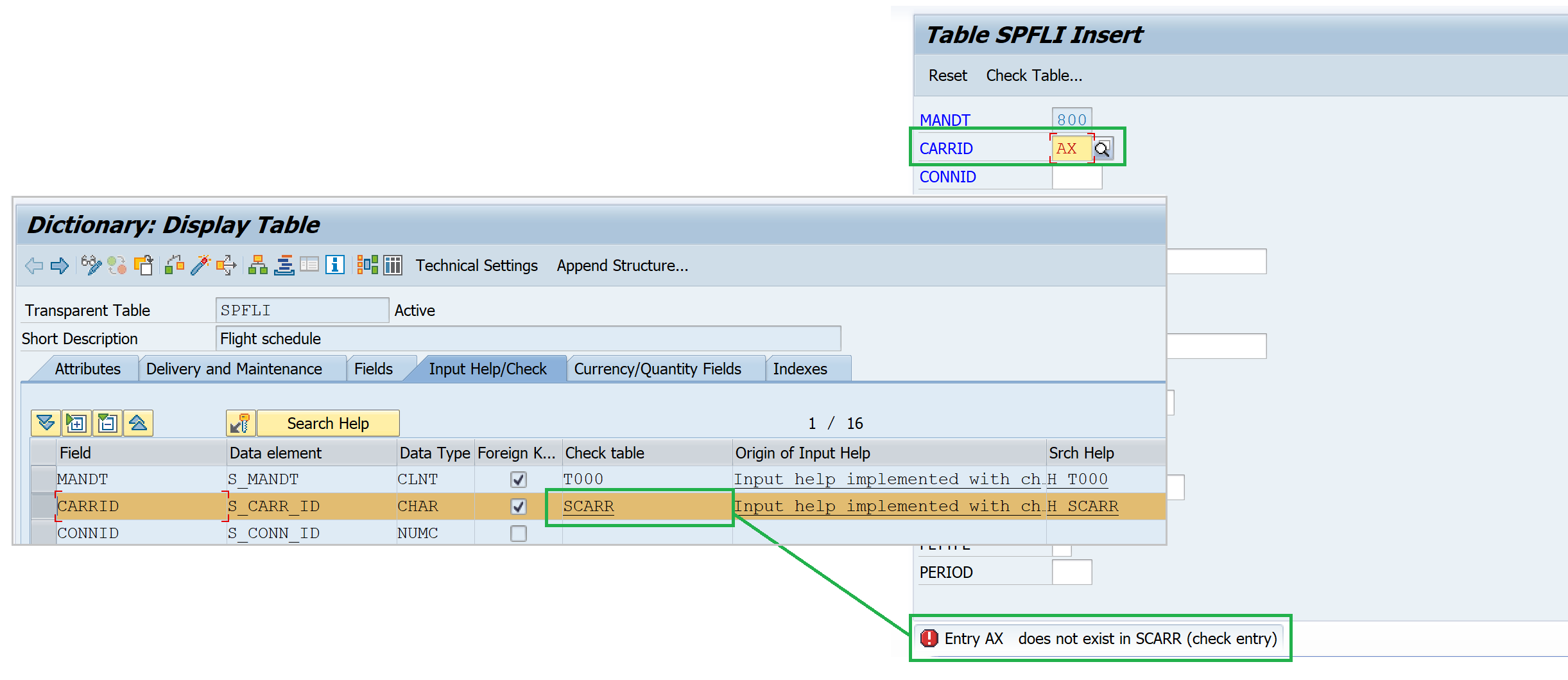
Vaule Table
- Provide values on F4 help for the table field.
- Part of the domain definition.
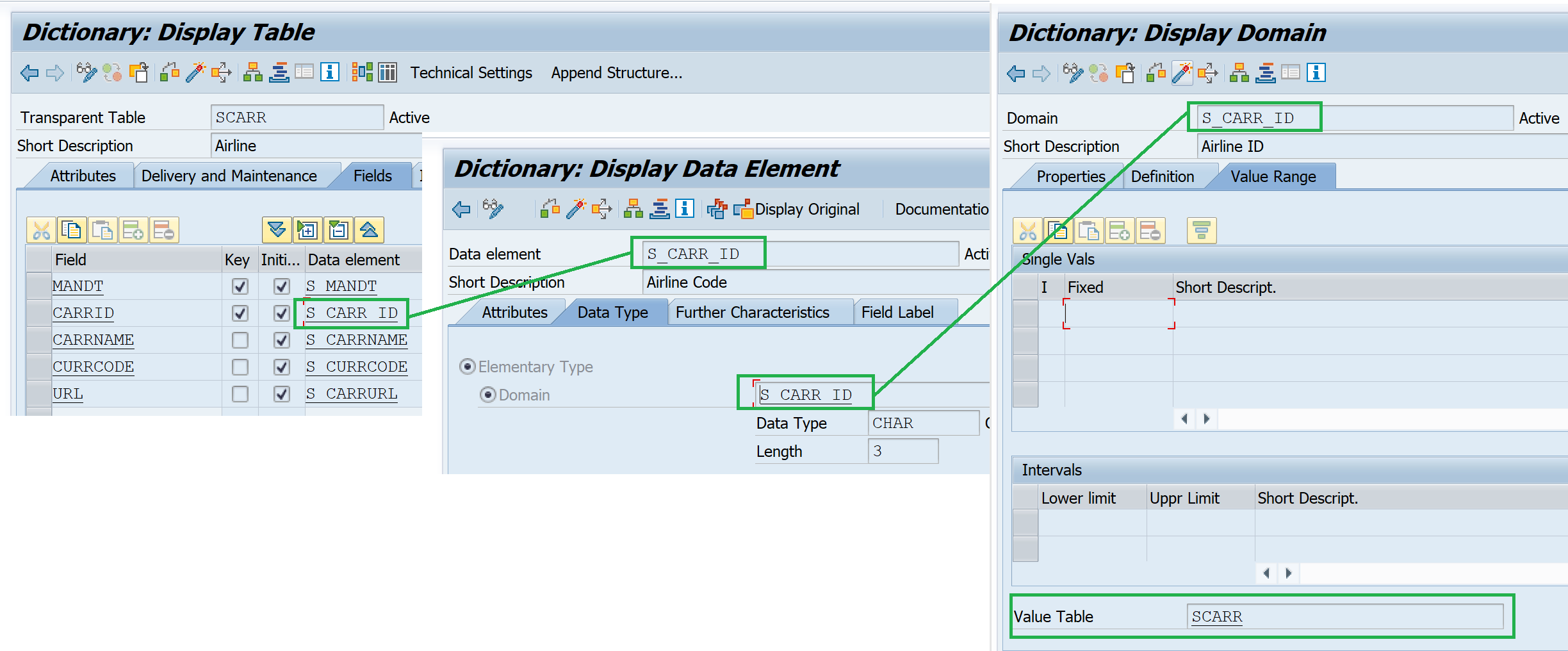
The table can be a value table for the key field from the same table, but the same is not possible for a check table.
Q12. How to provide a search help/F4 help/input help to the table field?
An input help can be assigned to a table or structure field in different ways:
- Attachment of a search help to the field
- Input help with the check table assigned to the field
- Attachment of a search help to the data element assigned to the field
- Fixed values from the domain assigned to the field
- Input help for data types DATS and TIMS
If more than one of these mechanisms is possible for a field, the first one mentioned is used.
1. Attachment of a search help to the field
Explicit search help can be assigned to the field in the Input Help/Check tab.
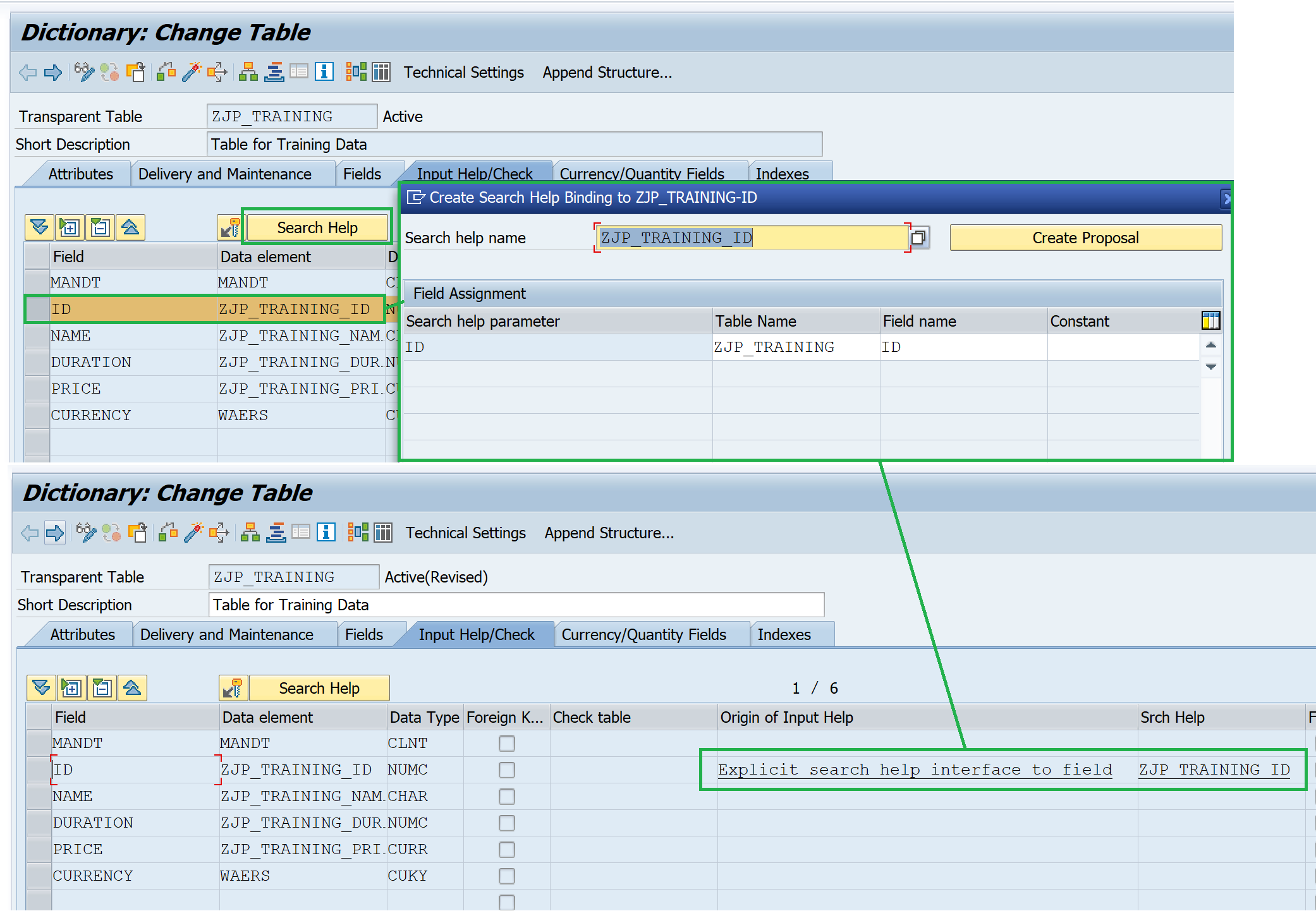
2. Input help with the check table assigned to the field
When a check table is assigned using a foreign key relation, automatic search help gets assigned and the table entries from the check table are shown.
Check table
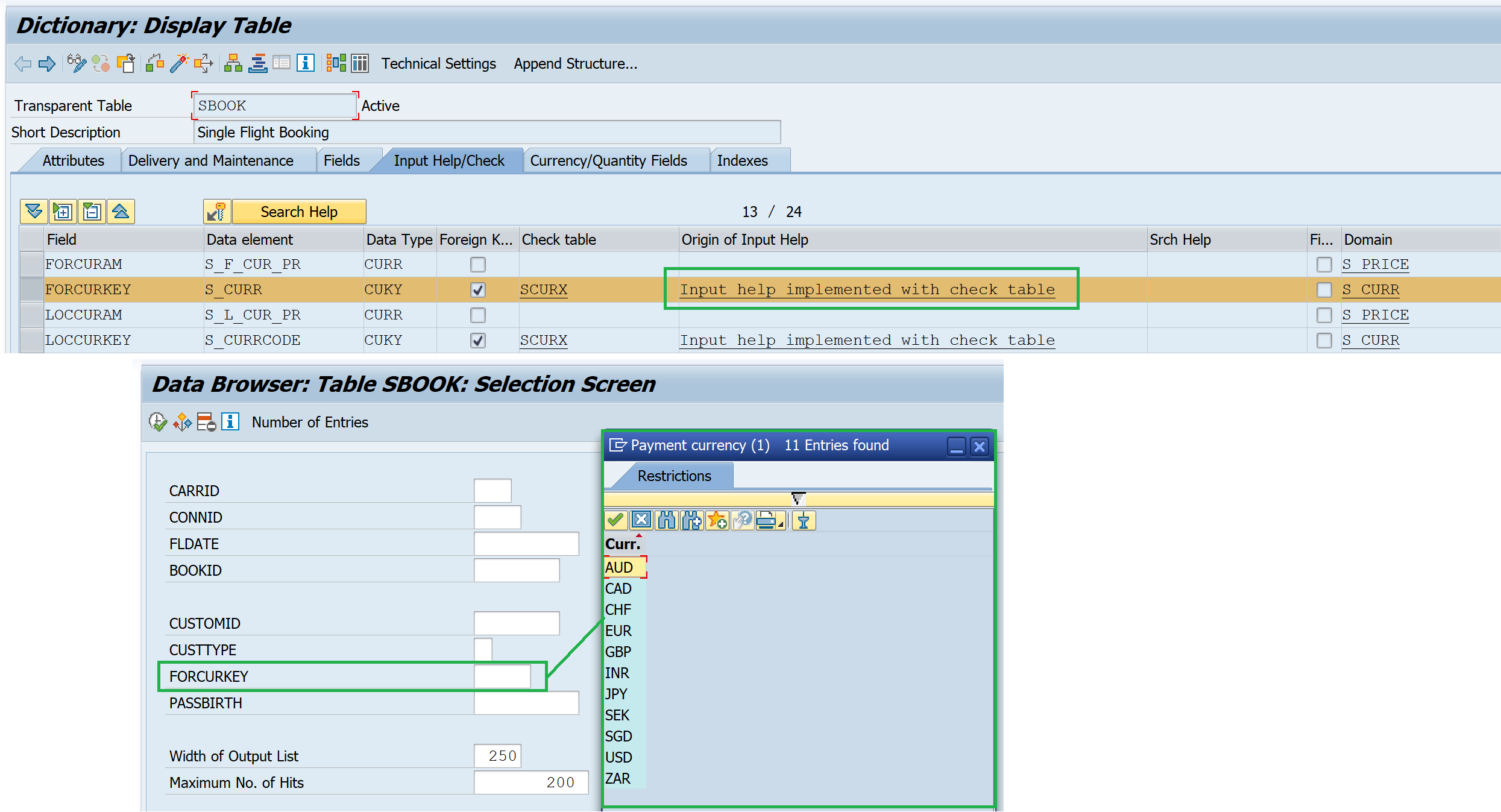
Domain – Value Table
When the same table is value table for the table field, the search help is automatically displayed, even though the help is not mentioned in the origin. However, the help will not appear in the table maintenance screen similar to help with check table.
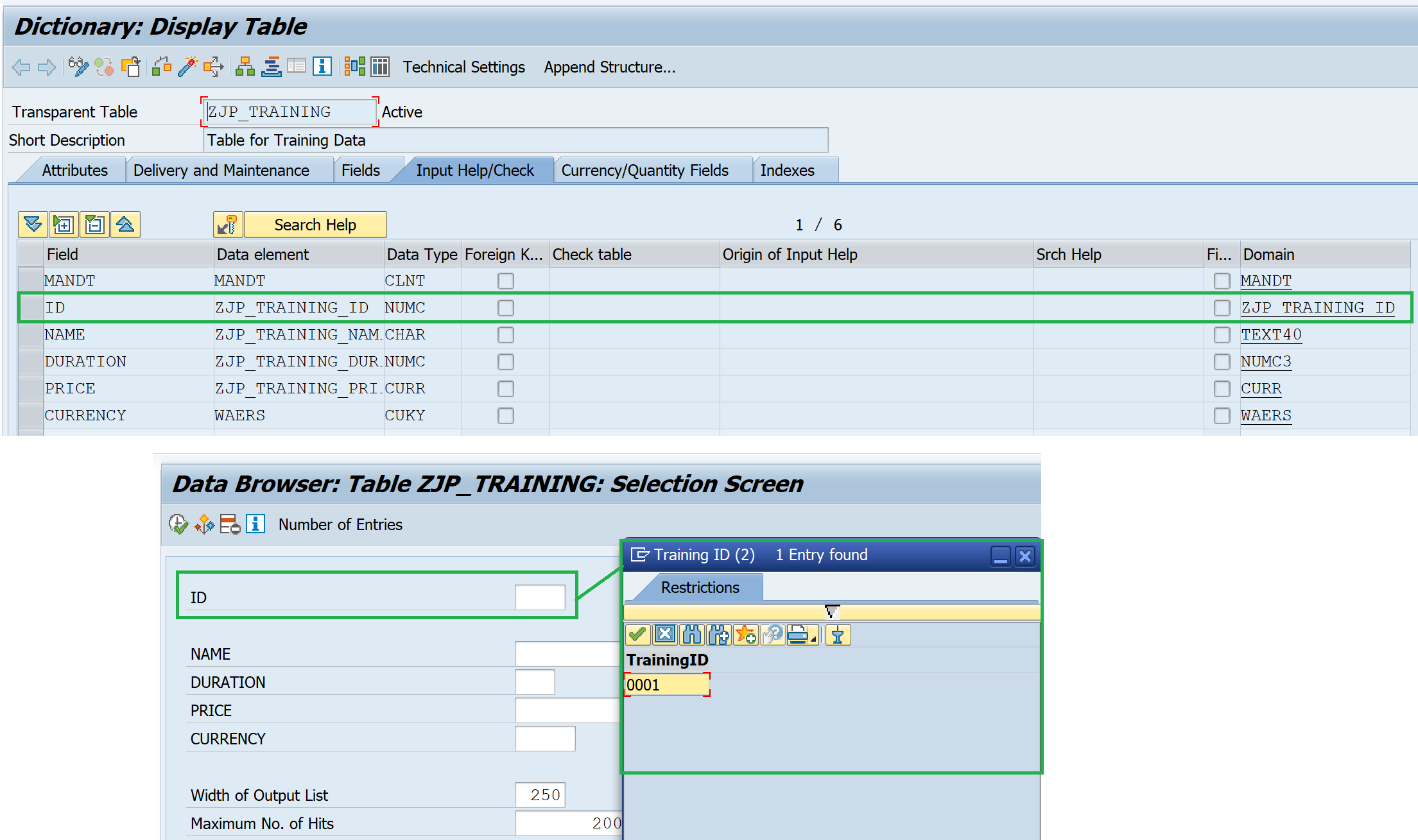
3. Attachment of a search help to the data element assigned to the field
The search help can be explicitly assigned in the data element in the Further Characteristic tab.
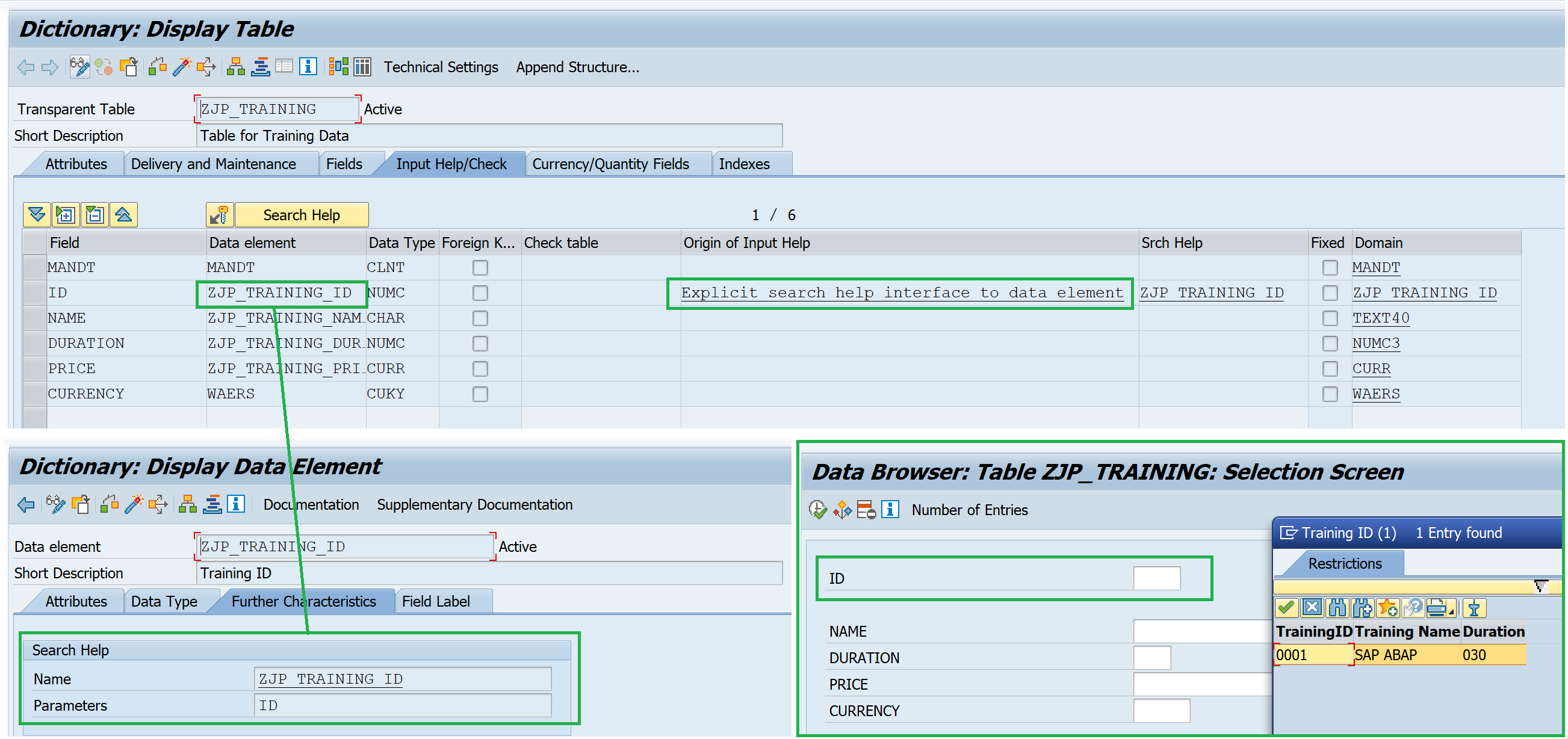
4. Fixed values from the domain assigned to the field
Fixed values from the domain are shown as search help entries.
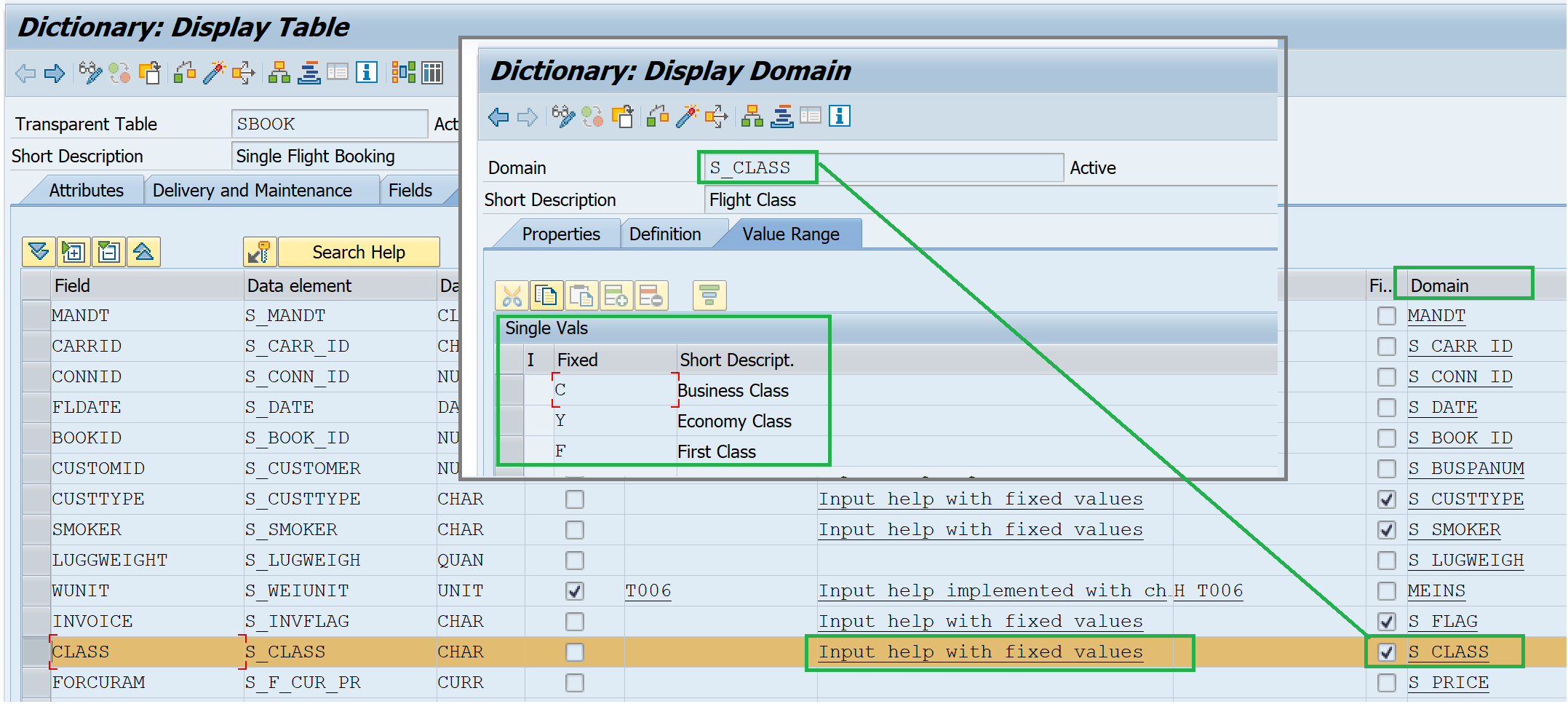
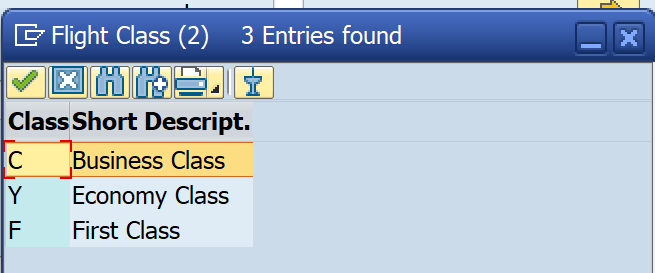
5. Input help for data types DATS and TIMS
Certain data types like the date and the time provide implicit/in built search help.
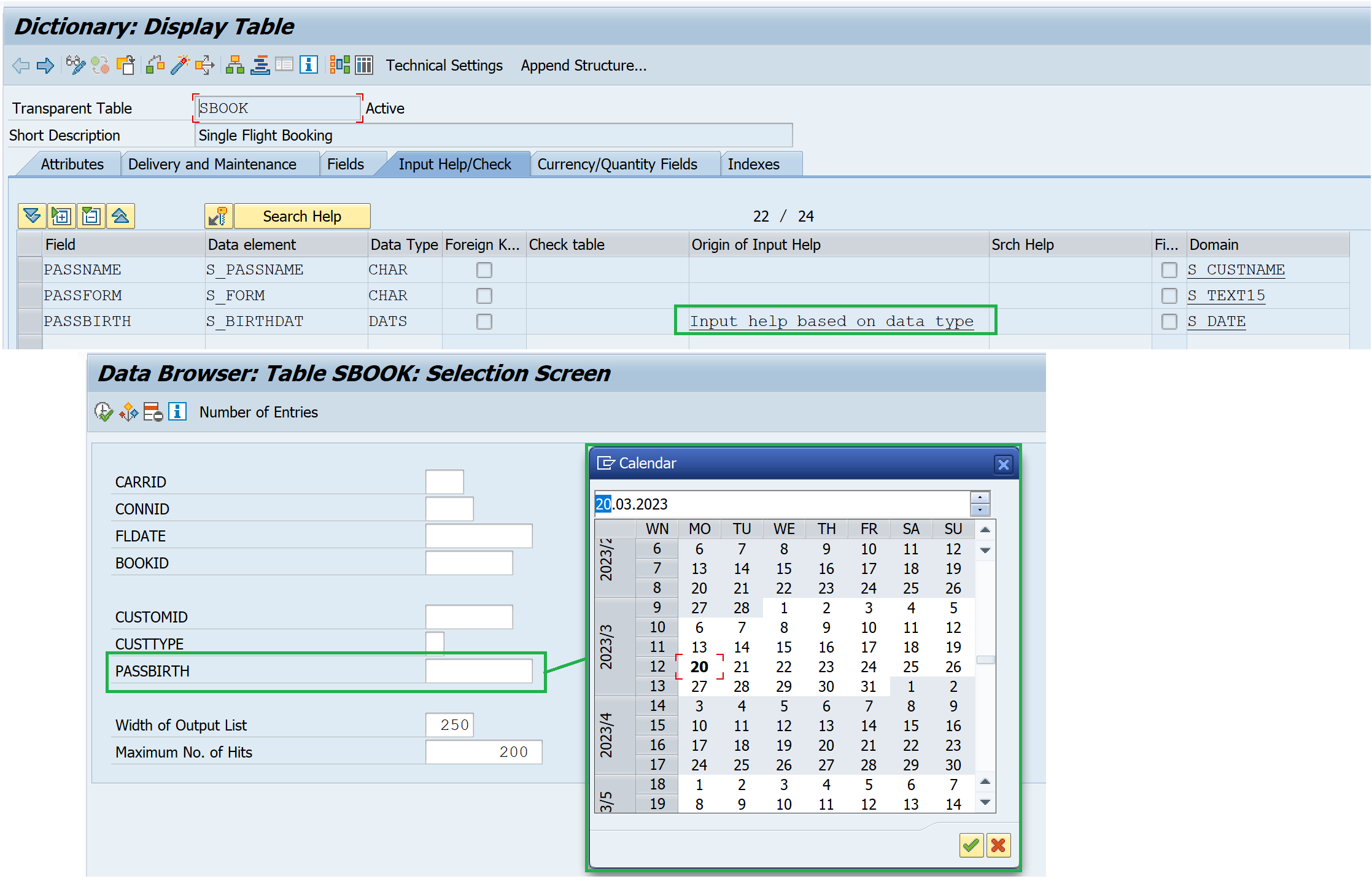
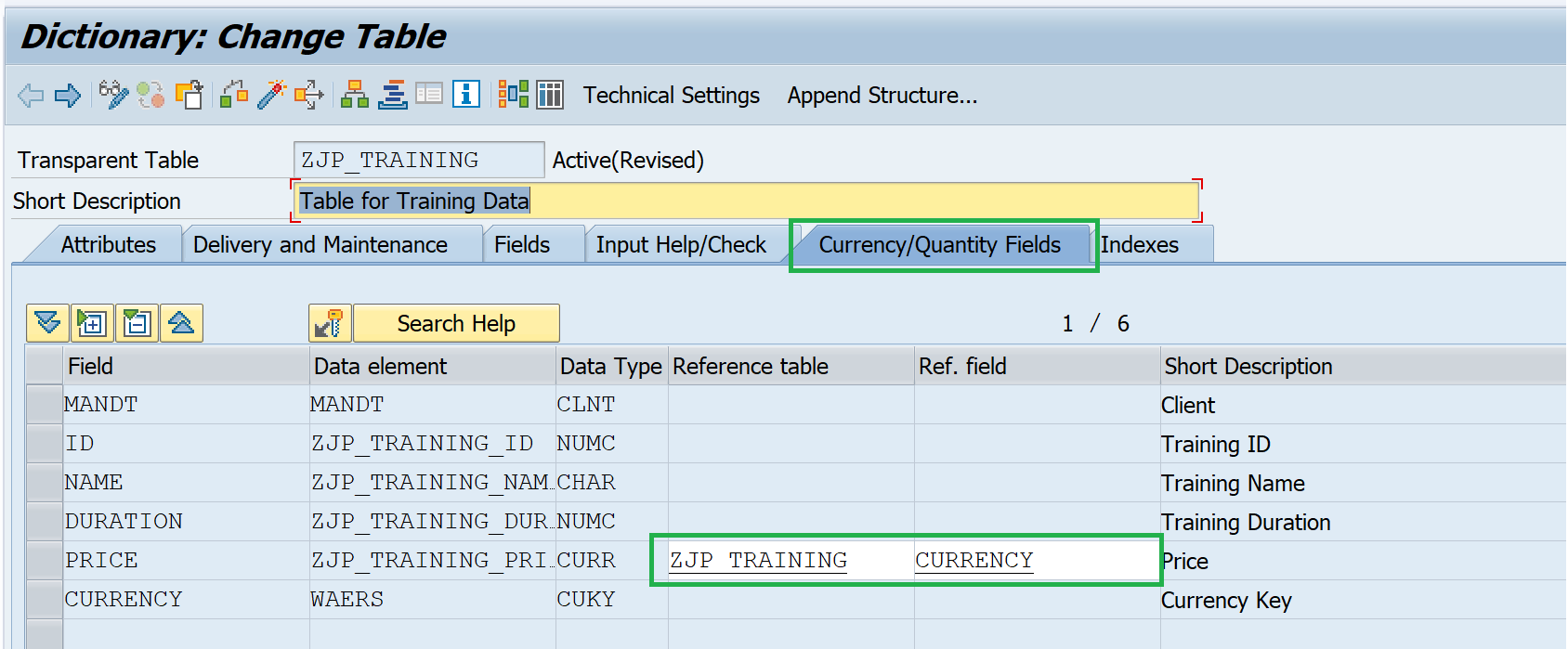
Q13. What is the additional information that we need to provide for any amount or quantity field?
Amount or currency fields need Currency Reference and Quantity field needs unit reference. This reference needs to be provided in the tab Currency/Quantity Fields where the reference table and reference field name is provided.
The table can be the same table or a different table. It can be a structure name as well.
Q14. What do we keep in mind while creating a secondary index on database table?
We can create secondary index on the transparent table, however we need to keep below in mind.
- Indexes can place a load on the system since they must be adjusted each time the table contents change.
- Each additional index therefore slows down the insertion of records in the table. Hence, tables which are frequently written should only have a few indexes.
- An index should only consist of a few fields; as a rule, no more than four.
- No more than five indexes should be created for any one table
- An index can only support those selection conditions that describe the search value positively, such as = or LIKE. The response times of conditions including <>, for example, are not improved by an index.
- Table fields with the predefined data types STRING and RAWSTRING must not be index fields.
- It is recommended that table fields with the data type FLTP are not index fields.
Creating secondary indexes is beneficial in the following cases:
- If table entries are to be selected based on fields that are not contained in an index, and the response times are very slow, a suitable secondary index should be created.
- The field or fields of a secondary index are so selective that each index entry corresponds to a maximum of 5% of the total number of table entries.
- The database table is accessed mainly to read entries.
- If only those fields are read that also exist in the index, the data does not need to be accessed a second time after the index access. If only a very small number of fields are selected, there can be significant efficiency gains if these fields are included in an index in their entirety.
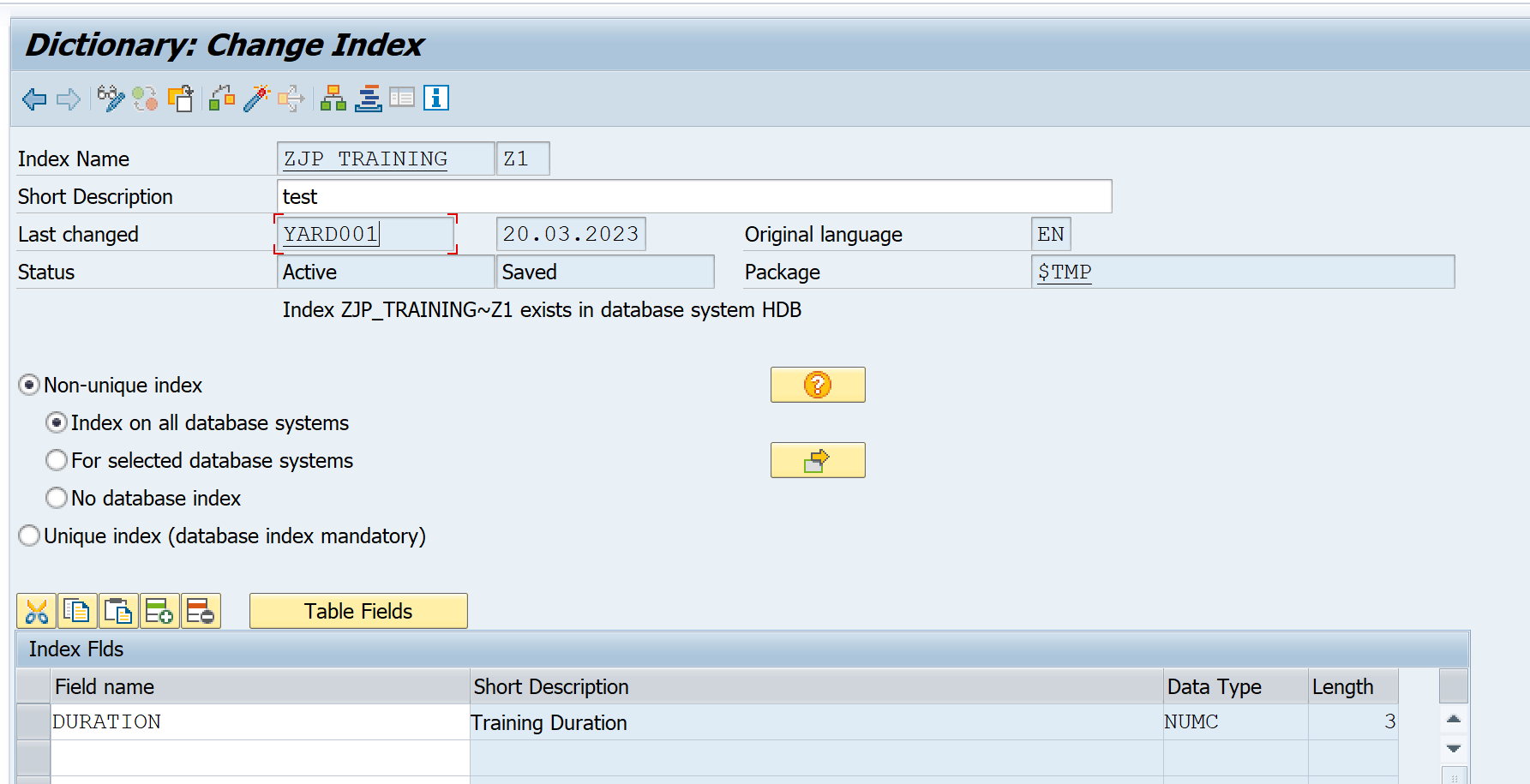
A cluster/pooled table does not exist as a separate physical table in the database and hence we can not create index on on cluster/pooled table.
Q15. What are the different types of database tables and what is the difference between them?
SAP has 3 types of database tables – Transparent tables, Pooled tables, and Cluster tables.
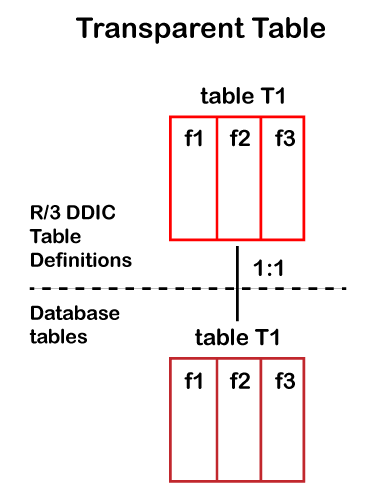
1. Transparent Tables
- The transparent table has the same name and structure in data dictionary and database
- It has a one-to-one relationship with a table in the database
- They can be accessed using open and native SQL
- Secondary indexes can be created
- They can hold any type of data like the master data, the transactional data, the configuration data, or the control data
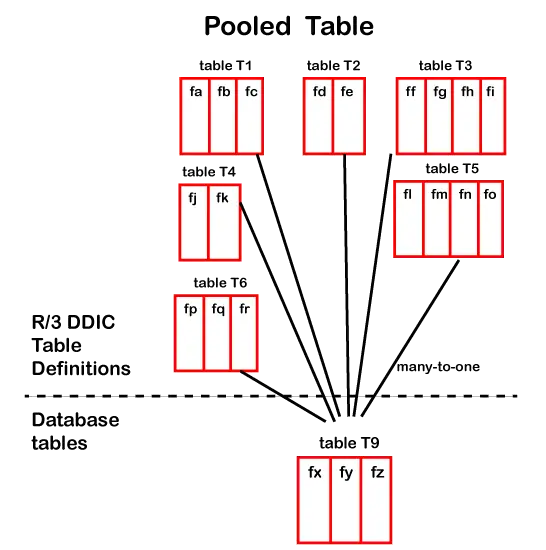
2. Pooled Tables
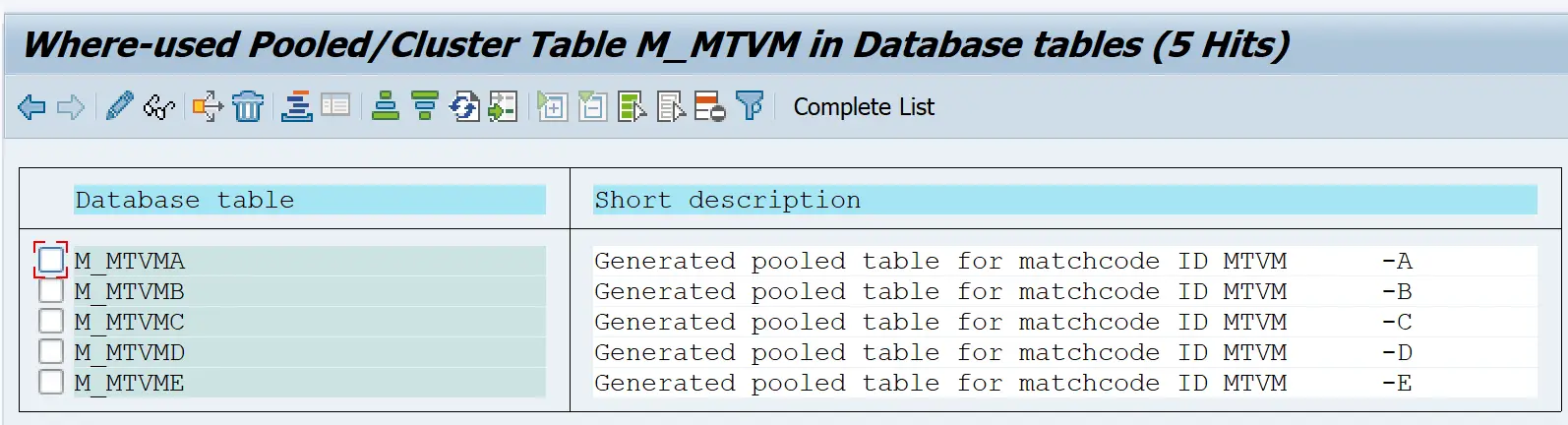
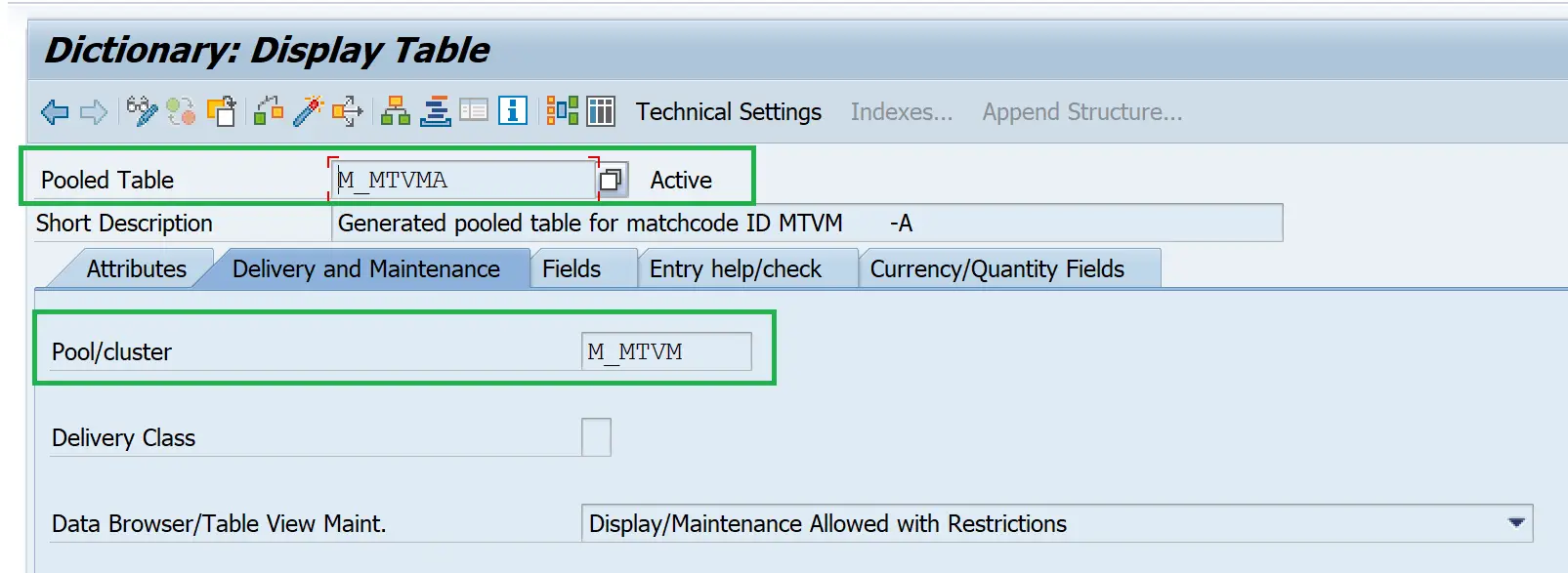
- The pooled table has many-to-one relationship i.e. many tables in the dictionary are stored in single table in the database i.e. multiple pooled tables are stored in a single table pool
- They are used to hold a large number of very small tables – this optimizes the usage of database space.
- They usually store customizing data or system data
- Primary key of each pooled table can begin with different fields
- Secondary indexes cannot be created
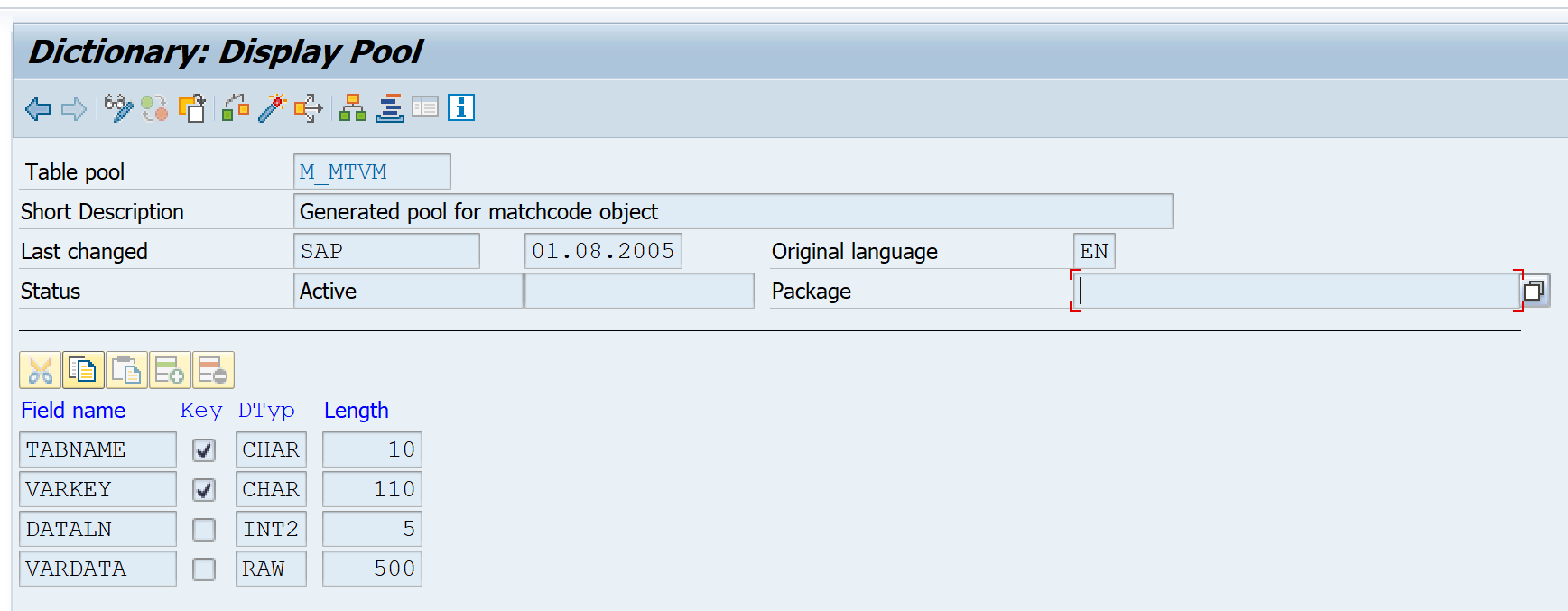
The definition of a table pool
| Field | Data type | Meaning |
| Tabname | CHAR(10) | Name of pooled table |
| Varkey | CHAR (n) | Contains the entries from all key fields of the pooled table record as a string, max. length for n is 110 |
| Dataln | INT2(5) | Length of the string in Vardata |
| Vardata | RAW (n) | Contains the entries from all data fields of the pooled table record as a string, max. length n depends on the database system used |
Table Pool
Pooled Tables within the table pool
3. Cluster Tables
- They are used to hold data from a few number of large tables
- It has a many-to-one relationship i.e. many tables in the dictionary are stored in single table in the database
- Primary key of each table begins with same fields or fields
- Secondary indexes cannot be created
- They would be used when the tables have primary key in common and data in these tables are all accesses simultaneously
A table cluster has the following structure:
| Field | Data type | Meaning |
| CLKEY1 | * | First key field |
| CLKEY2 | * | Second key field |
| … | … | … |
| CLKEYn | * | nth key field |
| Pageno | INT2(5) | Number of the continuation record |
| Timestamp | CHAR(14) | Time stamps |
| Pagelg | INT2(5) | Length of the string in Vardata |
| Vardata | RAW (n) | Contains the entries from the data fields of the assigned cluster tables as a string, max. length n depends on the database system used |
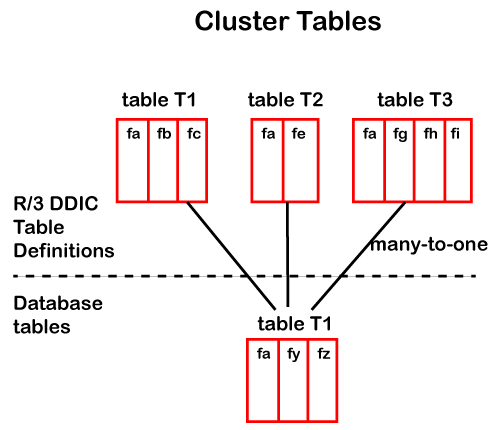
Note: with the HANA database the cluster tables are changed to transparent tables. For example, earlier BSEG used to be a cluster table but is now a transparent table.
Q16. What is difference in client dependent and client independent table?
Whenever we login to SAP system, we login to a specific client. Data in the R/3 system is categorized as client-dependent and client-independent.
- Client dependent data means the data which user creates in one client is limited to that client only and it is not accessible in other clients.
- Client Independent means data means the data which user creates in one client that is available in that as well as in other clients.
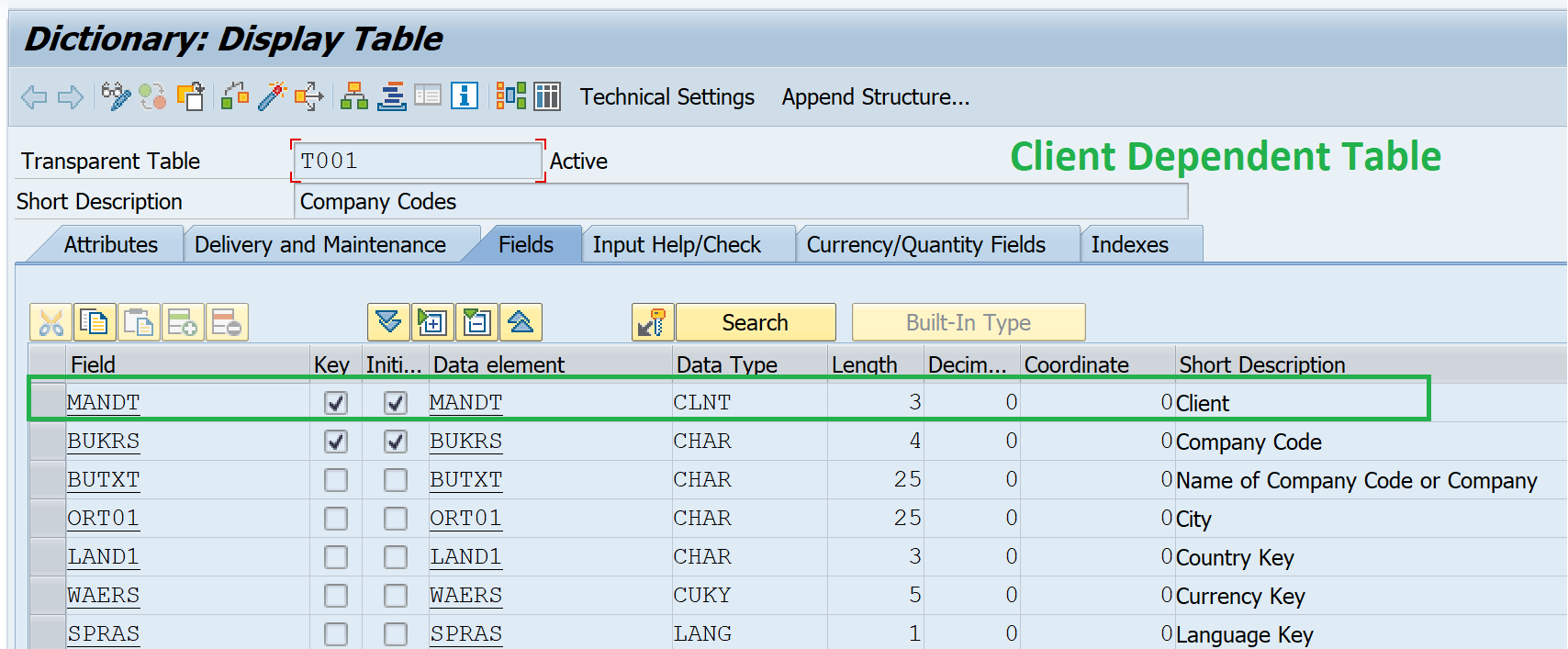
- Client Dependent Table
- They have first field called
MANDTof typeCLNTwhich contains the client number. - The data in this table will be different in each client
- They have first field called
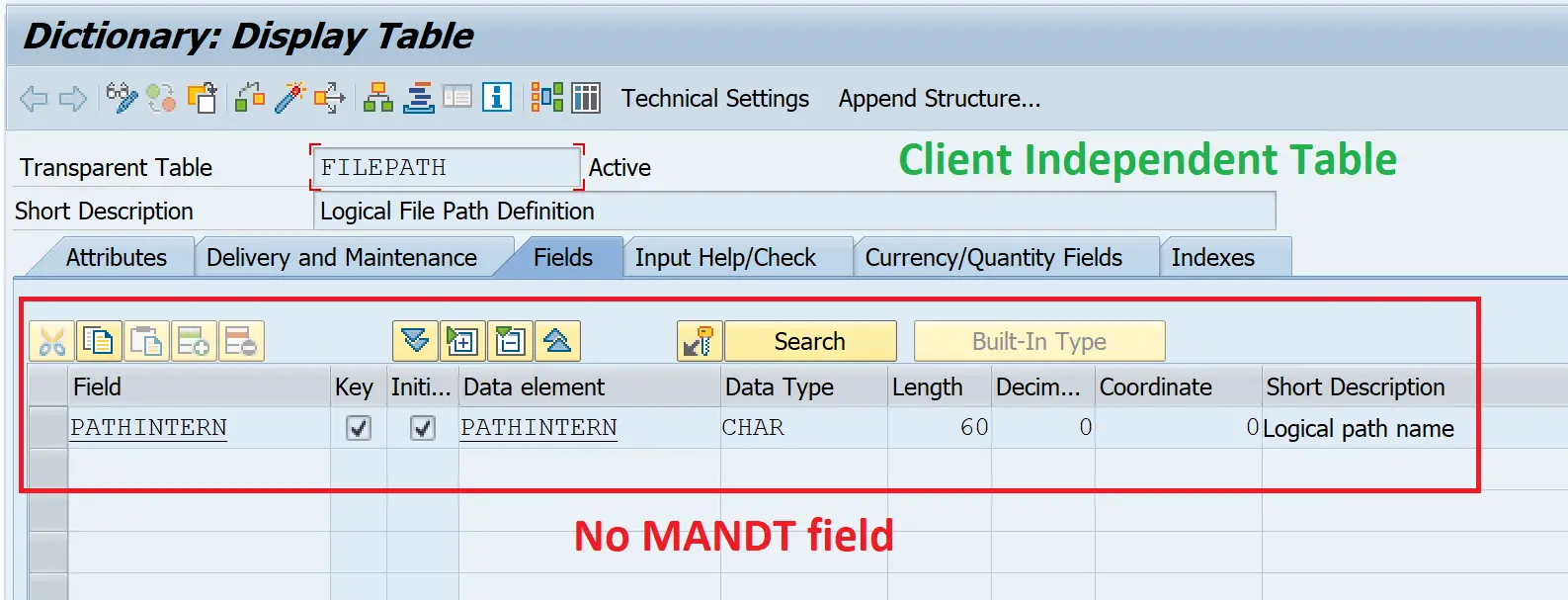
- Client Independent Table
- They don’t have that
MANDTfield in table. - All the clients have the same data in this table.
- They don’t have that
References:
Refer to Interview Preparation home page for list of all the resources.
Refer to Interview Preparation home page for list of all the resources.
If you like the content, please subscribe…
